Introducción
Este es el primer artículo de la serie “Desde el kernel hasta la orquestación”. El objetivo de los artículos es entender cómo funciona la orquestación de contenedores a más bajo nivel.
Uno de los beneficios de la ejecución y orquestación de contenedores es que no necesitamos preocuparnos por cómo se ejecutan a bajo nivel en la infraestructura.
Es genial tener una abstracción de cómo funciona la tecnología para poder centrarnos en añadir los servicios y la funcionalidad necesaria para nuestras aplicaciones, pero en ocasiones es importante tener el conocimiento de cómo funciona esta tecnología para entender lo que está pasando cuando tenemos una incidencia o necesitamos depurar un problema.
En el siguiente diagrama podemos ver el stack de tecnologías utilizado para la ejecución y orquestación de contenedores. En este post y en los siguientes los iremos desgranando para conocer cómo funcionan entre ellas:
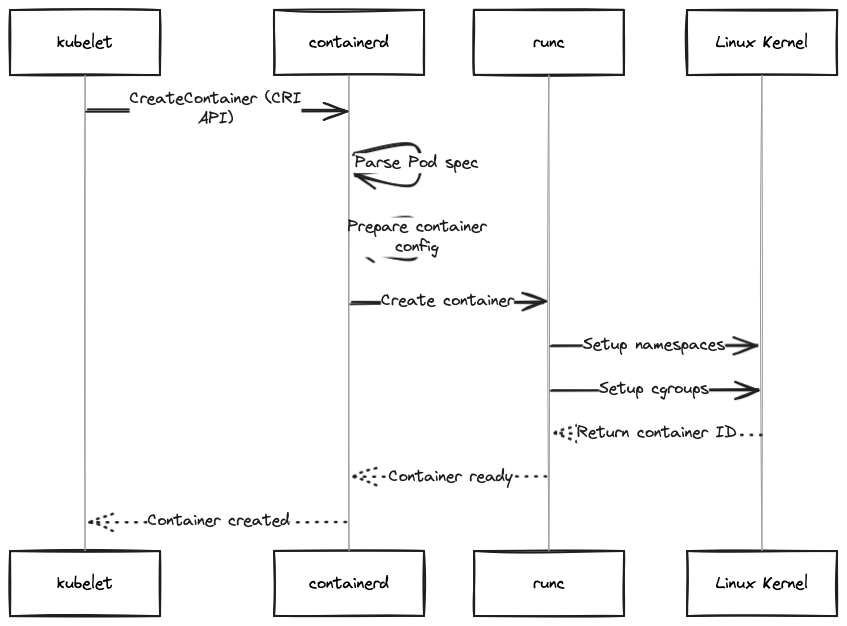
Para comenzar, vamos a hablar sobre namespaces y cgroups (control groups), los cuales son la base de la virtualización de procesos en sistemas operativos que utilizan Linux como base.
Namespaces y cgroups están disponibles desde 2002 y 2008, respectivamente. Utilizándolos de manera conjunta, podemos ejecutar de manera aislada procesos en Linux; además, son las tecnologías utilizadas para la ejecución de contenedores en Linux.
Namespaces (Linux)
No confundir los namespaces en Linux con los namespaces de Kubernetes.
El kernel de Linux incorpora una funcionalidad llamada namespaces, la cual permite aislar y limitar el acceso de un proceso a algunos recursos del sistema.
De esta manera, el proceso puede ejecutarse dentro de su propio entorno sin interferir ni acceder a otros recursos de otros procesos.
Esta funcionalidad se añadió al kernel de Linux en la versión 2.6.24 (2008) y es la base para poder ejecutar contenedores a través de aplicaciones como Docker, LXC, containerd…
Algunos de los tipos de namespaces disponibles en el kernel son los siguientes:
- cgroup namespace (kernel 4.6 - 2016): Permite aislar la vista y manipulación de los grupos de control (cgroups) para los procesos dentro del namespace. Así, los procesos solo pueden gestionar y ver los cgroups a los que pertenecen, sin acceder a los del sistema anfitrión o de otros contenedores. Esto mejora la seguridad y el aislamiento de recursos.
- Inter-process communication (IPC) namespace (kernel 2.4.19 - 2006): Aísla los mecanismos de comunicación entre procesos, como semáforos, colas de mensajes y memoria compartida. Los procesos dentro de un namespace IPC solo pueden comunicarse entre sí, evitando interferencias o accesos no autorizados a recursos IPC de otros namespaces.
- Mount namespace (kernel 2.4.19 - 2002): Permite gestionar qué sistemas de archivos están montados y disponibles para los procesos dentro del namespace. Cada mount namespace puede tener su propio conjunto de puntos de montaje, posibilitando que los contenedores tengan vistas independientes del sistema de archivos y aumentando el aislamiento y la flexibilidad en la gestión de almacenamiento.
- Network namespace (kernel 2.6.29 - 2009): Virtualiza los elementos de red disponibles. Al crear el namespace, solo está disponible el dispositivo
loopback. Cada dispositivo solo puede estar asociado a un namespace. Cada namespace tiene su propia IP, tabla de enrutamiento y firewall. - PID namespace (kernel 2.6.24 - 2008): Permite aislar el espacio de identificadores de procesos (PID). Los procesos dentro de un PID namespace ven solo los procesos que existen en ese namespace, y el primer proceso creado tiene PID 1, similar al proceso init en un sistema Linux tradicional. Esto permite que los contenedores ejecuten sus propios árboles de procesos de manera independiente y facilita la gestión de procesos huérfanos.
- Time namespace (kernel 5.6 - 2020): Permite que los procesos de cada namespace utilicen diferentes offsets de tiempo.
- Unix time-sharing (UTS) namespace (kernel 2.6.19 - 2006): Permite que los procesos dentro de un namespace tengan su propio nombre de host (
hostname) y nombre de dominio (domainname). Esto es útil para que los contenedores tengan identificadores de red independientes, aislando la identidad del sistema dentro de cada contenedor. - User namespace (kernel 3.8 - 2013): Proporciona aislamiento de usuarios y grupos. Los procesos pueden tener diferentes identificadores de usuario (UID) y grupo (GID) dentro del namespace respecto al sistema anfitrión. Esto permite, por ejemplo, que un proceso tenga privilegios de root dentro del contenedor pero sea un usuario sin privilegios fuera de él, mejorando la seguridad.
cgroups (control groups)
cgroups es la abreviación de control groups. Esta funcionalidad del kernel de Linux permite establecer el control sobre la cantidad de recursos que un proceso puede utilizar. De esta manera, evitamos que un proceso que necesite hacer un uso intensivo de la CPU pueda interferir con otros procesos que estamos ejecutando en la misma máquina. Las principales características son:
- Limitación de recursos: permite establecer límites sobre el uso de CPU, memoria, I/O y número máximo de archivos abiertos por grupo de procesos.
- Priorización: posibilita asignar diferentes prioridades de acceso a los recursos entre distintos grupos de procesos.
- Accounting (facturación): proporciona métricas detalladas sobre el consumo de recursos, útiles para monitorización y facturación.
- Control: permite pausar (congelar) o reanudar la ejecución de un grupo de procesos.
- Jerarquía: en cgroup v1, los grupos pueden organizarse jerárquicamente, permitiendo heredar límites y configuraciones entre padres e hijos.
Esta versión presenta algunos problemas de uso:
- Es complejo administrar múltiples jerarquías.
- Inconsistencia entre diferentes controladores.
- Dificultad para delegar privilegios de manera segura.
En 2016, con la versión del kernel 4.5, llega la versión 2 de cgroup. Las principales mejoras son:
- Jerarquía unificada: todos los controladores que componen cgroup comparten una única jerarquía; la estructura es más simple y coherente. Cada proceso pertenece solo a un cgroup.
- Actualización de los controladores que componen cgroup:
- CPU: Control unificado de uso de CPU (bandwidth y cuotas).
- Memoria: Gestión avanzada de memoria, con soporte para swapping y límites más precisos.
- IO: Sustituye a blkio, ofreciendo una contabilidad y control de entrada/salida más eficiente.
- RDMA (Remote Direct Memory Access): Permite a los procesos acceder directamente a la memoria de otros sistemas a través de la red, sin intervención del procesador ni del sistema operativo remoto. Esto mejora el rendimiento en aplicaciones que requieren baja latencia y alto ancho de banda, como bases de datos distribuidas o sistemas de almacenamiento de alto rendimiento.
- PIDS: Permite establecer límites en la cantidad de procesos que puede crear un grupo, evitando el agotamiento de recursos por exceso de procesos.
- Funcionalidades mejoradas en CPU y memoria: cgroup v2 ofrece un control más granular y eficiente sobre el uso de CPU y memoria. Por ejemplo, permite definir cuotas y prioridades de CPU de forma más precisa, así como establecer límites de memoria más estrictos y gestionar mejor situaciones de presión de memoria. Además, la gestión de memoria swap es más flexible, lo que ayuda a evitar situaciones de OOM (Out Of Memory).
- Delegación segura: cgroup v2 introduce mecanismos más robustos para delegar la administración de subgrupos a procesos sin privilegios. Esto significa que los usuarios pueden gestionar sus propios recursos y crear jerarquías de cgroups dentro de los límites establecidos por el administrador del sistema, sin necesidad de privilegios elevados. Esta funcionalidad mejora la seguridad y facilita la multi-tenencia, permitiendo que diferentes usuarios o aplicaciones gestionen sus propios recursos de manera aislada y controlada, sin comprometer la integridad del sistema anfitrión.
- Semántica mejorada: los límites de recursos son más predecibles y consistentes entre los distintos controladores, lo que facilita la configuración y reduce comportamientos inesperados. Además, se han mejorado las métricas de consumo y la gestión de situaciones de OOM (Out Of Memory), permitiendo una monitorización y respuesta más precisa ante el agotamiento de recursos.
Gracias a esta versión se ha mejorado el aislamiento de recursos entre contenedores y se permite limitar los recursos de una manera más precisa.
Desde la versión 1.25, en Kubernetes cgroups v2 está activado por defecto.
Ejemplo práctico
Vamos a comprobar cómo podemos ejecutar procesos limitando el uso de CPU y memoria.
Antes de continuar, verifica si tu máquina utiliza cgroups v2 ejecutando el comando mount | grep cgroup.
- Si ves múltiples montajes, estás usando cgroups v1.
- Si ves solo un montaje de tipo cgroup2, estás usando cgroups v2.
Otra forma de comprobarlo es ejecutar ls /sys/fs/cgroup/cgroup.controllers. Si el comando falla, tienes cgroups v1; si muestra contenido, tienes cgroups v2.
Estructura de directorios en cgroups v1:
/sys/fs/cgroup/
├── blkio/ # Control de I/O de bloques
├── cpu/ # Control de CPU
├── cpuacct/ # Contabilidad de CPU
├── memory/ # Control de memoria
├── devices/ # Control de dispositivos
├── freezer/ # Congelar/descongelar procesos
├── net_cls/ # Clasificación de red
├── pids/ # Control de número de procesos
└── systemd/ # Jerarquía de systemd
Estructura de directorios en cgroups v2:
/sys/fs/cgroup/
├── cgroup.controllers # Controladores disponibles
├── cgroup.procs # Procesos en este cgroup
├── cgroup.subtree_control # Controladores habilitados
├── cpu.max # Límite máximo de CPU
├── memory.max # Límite máximo de memoria
├── io.max # Límite máximo de I/O
├── pids.max # Límite máximo de procesos
└── user.slice/ # Jerarquía de systemd
├── system.slice/
└── docker.slice/
El directorio /sys/fs/cgroup/ es el estándar para las interfaces del kernel:
sys: Interfaces del kernelfs: Sistemas de archivos especialescgroup: Subsistema cgroups
Al crear un directorio en /sys/fs/cgroup/, se generan automáticamente los archivos necesarios para configurar un nuevo cgroup:
sudo mkdir /sys/fs/cgroup/my-group/

El número de archivos puede variar según los controladores activos. Puedes consultar los controladores disponibles con cat /sys/fs/cgroup/cgroup.controllers.
Existen varios métodos para configurar un cgroup:
- Editar directamente los archivos.
- Usar los binarios del paquete cgroup-tools (libcgroup).
- Utilizar el comando
systemd-run.
Para limitar la memoria de un cgroup:
echo "10M" | sudo tee /sys/fs/cgroup/my-group/memory.max
Para limitar el uso de CPU al 25%:
echo "25000 100000" | sudo tee /sys/fs/cgroup/my-group/cpu.max
Puedes comprobar su funcionamiento utilizando la herramienta stress-ng:
sudo bash -c "echo $$ > /sys/fs/cgroup/my-group/cgroup.procs && exec stress-ng --vm 1 --vm-bytes 200M"

También puedes usar los comandos de cgroup-tools (libcgroup):
| Comando | Descripción | Ejemplo |
|---|---|---|
cgcreate | Crear nuevos cgroups | cgcreate -g memory:/my-group |
cgdelete | Eliminar cgroups | cgdelete memory:/my-group |
cgset | Configurar parámetros de cgroups | cgset -r memory.max=100M my-group |
cgget | Obtener el valor de un parámetro | cgget -r memory.max my-group |
cgexec | Ejecutar comando en un cgroup | cgexec -g memory:my-group firefox |
sudo cgcreate -g memory,cpu:/my-group
sudo cgset -r memory.max=10M my-group
sudo cgset -r cpu.max="25000 100000" my-group
sudo cgexec -g memory,cpu:my-group stress-ng --vm 1 --vm-bytes 200M
systemd-run es la herramienta recomendada para gestionar procesos, ya que systemd es el principal gestor de cgroups (v2) en Linux y simplifica la ejecución de comandos bajo restricciones de recursos:
systemd-run --scope -p MemoryMax=10M stress-ng --vm 1 --vm-bytes 200M --timeout 30s
Otro ejemplo más avanzado, limitando CPU, memoria e IO:
systemd-run --unit=backup-job \
-p CPUQuota=20% \
-p IOWeight=50 \
-p MemoryMax=1G \
tar czf /backup/system-$(date +%Y%m%d).tar.gz /home
Podemos utilizar de manera conjunta cgroups y namespaces. El siguiente ejemplo crea un nuevo cgroup, limitando la memoria a 256 megabytes, el uso de CPU al 25% y el número máximo de procesos a 10:
sudo mkdir /sys/fs/cgroup/my-container
echo "+memory +cpu +pids" | sudo tee /sys/fs/cgroup/cgroup.subtree_control
echo "256M" | sudo tee /sys/fs/cgroup/my-container/memory.max
echo "25000 100000" | sudo tee /sys/fs/cgroup/my-container/cpu.max
echo "10" | sudo tee /sys/fs/cgroup/my-container/pids.max
sudo unshare --pid --net --mount --uts --fork bash -c "
echo \$\$ > /sys/fs/cgroup/my-container/cgroup.procs
hostname my-container
mount -t proc proc /proc
exec bash
"
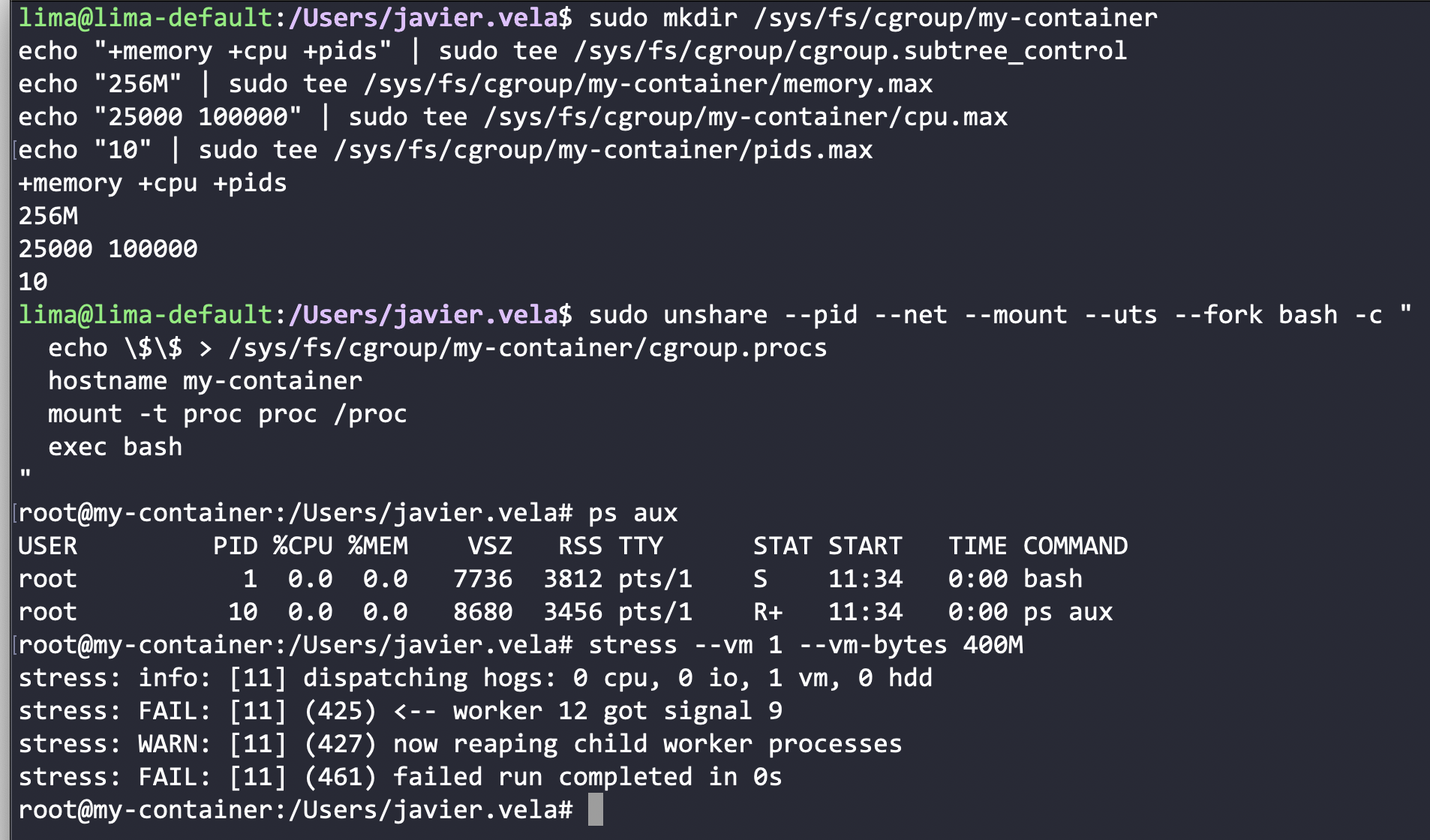
Estos ejemplos permiten experimentar y comprender de forma práctica cómo los cgroups y namespaces trabajan juntos para aislar y limitar recursos en Linux.
Resumen
Aunque puedan parecer similares, namespaces y cgroups cumplen roles complementarios en la virtualización de procesos en Linux:
- Namespaces proporcionan aislamiento: cada contenedor tiene su propia vista del sistema operativo, incluyendo red, procesos, sistema de archivos, usuarios, etc. Esto significa que los procesos dentro de un contenedor no pueden ver ni interactuar directamente con los recursos de otros contenedores o del sistema anfitrión.
- cgroups proporcionan control de recursos: permiten limitar, priorizar y monitorizar el uso de recursos como CPU, memoria, almacenamiento y procesos para cada grupo de procesos. Así, se evita que un contenedor consuma todos los recursos del sistema y afecte a los demás.
La combinación de ambas tecnologías es lo que permite ejecutar múltiples aplicaciones de forma segura, aislada y eficiente en el mismo kernel Linux. Cada contenedor se ejecuta en su propio espacio aislado (gracias a los namespaces) y con recursos controlados (gracias a los cgroups).
En resumen, los namespaces aíslan qué puede ver y hacer un proceso, mientras que los cgroups controlan cuánto puede consumir. Juntos, hacen posible la ejecución de contenedores tal y como los conocemos hoy.
Referencias
- https://earthly.dev/blog/namespaces-and-cgroups-docker/
- https://en.wikipedia.org/wiki/Cgroups
- https://en.wikipedia.org/wiki/linux_namespaces
- https://kubernetes.io/docs/concepts/architecture/cgroups/
- https://lwn.net/Articles/259217/
- https://man7.org/linux/man-pages/man7/cgroups.7.html
- https://www.redhat.com/en/blog/cgroups-part-four
