Contenedores: Desde el kernel hasta la orquestación - kubernetes
Parece trivial ejecutar un contenedor, pero la realidad es mucho más compleja. En la tercera parte de la saga “Desde el kernel hasta la orquestación” nos adentramos en la orquestación de contedores.

Introducción
En la tercera parte de la saga “Desde el kernel hasta la orquestación” nos adentramos en la orquestación de contenedores.
Si todavía no has leído los artículos anteriores, te recomiendo empezar por el primero, donde hablo de namespaces (Linux) y control groups (cgroups), herramientas de bajo nivel incluidas en el kernel de Linux para aislar procesos y limitar el acceso a los recursos del host: cgroups y namespaces.
En el segundo artículo de la saga, explico cómo herramientas de más alto nivel como runc y containerd crean una capa de abstracción que permite ejecutar “contenedores” de manera más sencilla y segura: runc y containerd.
En este post voy a explicar cómo Kubernetes interactúa con todas estas herramientas para orquestar contenedores de manera eficiente y escalable.
Kubernetes
Kubernetes es un orquestador de contenedores que monitoriza su estado y ejecuta las acciones necesarias para mantenerlos en el estado deseado. Permite escalar y actualizar aplicaciones de forma automática, facilitando la orquestación de soluciones complejas.
Kubernetes dispone de dos tipos de nodos:
Control Plane: se encarga de ejecutar los procesos que gestionan y orquestan los contenedores de usuario.
Worker: ejecuta los contenedores de usuario.
En los nodos de tipo control plane se ejecutan los procesos críticos de Kubernetes que permiten monitorizar y ejecutar las acciones necesarias para mantener los contenedores en el estado definido. Estos procesos son:
etcd: almacenamiento distribuido de datos clave-valor donde Kubernetes guarda toda la información de estado del clúster.
kube-apiserver: expone la API de Kubernetes y es el punto de entrada para todas las operaciones (ej. crear un Pod o consultar su estado).
kube-scheduler: asigna los pods a los nodos disponibles según las necesidades de recursos y restricciones.
kube-controller-manager: ejecuta los controladores que monitorizan el estado del clúster y realizan acciones para mantener el estado deseado.
En cada nodo de tipo worker se ejecutan dos procesos principales:
kubelet: agente que se encarga de gestionar los pods y contenedores en el nodo, asegurando que se ejecuten correctamente.
kube-proxy: gestiona la red y el balanceo de carga para exponer los servicios de Kubernetes dentro y fuera del clúster.
Un Pod es la unidad más pequeña de despliegue en Kubernetes. Representa uno o varios contenedores que comparten el mismo espacio de red, almacenamiento y configuración. Todos los contenedores de un Pod se ejecutan en el mismo nodo y pueden comunicarse entre sí a través de
localhost.
El flujo de creación de un Pod en Kubernetes sería el siguiente:
Cuando un usuario crea un nuevo Pod (uno o más contenedores trabajando entre sí), interactúa con
kube-apiserver. Una vez procesada la solicitud,kube-schedulerdecide en qué nodo de tipo worker debe ejecutarse.La solicitud es recibida por
kubelet, que realiza las operaciones necesarias para comenzar la ejecución de los contenedores a través del Container Runtime Interface (CRI).
El siguiente diagrama muestra la arquitectura que vamos a explorar en el post, desde el control plane de Kubernetes hasta los procesos del kernel:

Container Runtime Interface (CRI)
Una de las principales características de Kubernetes es la interoperabilidad con diferentes runtimes de contenedores. Para lograrlo, Kubernetes define Container Runtime Interface (CRI), un estándar basado en gRPC que permite a kubelet comunicarse con distintos motores de ejecución de contenedores (como containerd, CRI-O, Docker, etc.) de manera uniforme y desacoplada.
CRI facilita la integración de nuevos runtimes sin necesidad de modificar el código, promoviendo así la flexibilidad y la evolución del ecosistema de contenedores.
Una vez que kubelet recibe la petición para ejecutar un nuevo Pod, realiza las siguientes acciones:
Crear el namespace, cgroups y configurar la red.
Realizar pull de la imagen o imágenes en caso de que fuera necesario.
Crear el container
Ejecutar el container
Para ello, la interfaz proporciona las siguientes interfaces a través de los servicios RuntimeService e ImageService.
Puedes encontrar la definición de las interfaces en el siguiente enlace:
https://github.com/kubernetes/cri-api/blob/master/pkg/apis/runtime/v1/api.proto
A continuación te describo algunos de los métodos más importantes:
El PodSandbox es el entorno compartido donde vivirán todos los contenedores del Pod:
RunPodSandbox– Crea los namespaces, configura la red y prepara el entorno.StopPodSandbox– Detiene todos los procesos y libera los recursos de red.RemovePodSandbox– Limpia completamente el sandbox.
Gestión individual de cada contenedor dentro del PodSandbox:
CreateContainer– Prepara el contenedor con su configuración específica.StartContainer– Inicia la ejecución del proceso principal.StopContainer– Detiene el contenedor con un período de gracia.RemoveContainer– Elimina completamente el contenedor.
Monitoreo continuo del estado y rendimiento:
ContainerStatus/PodSandboxStatus– Estado actual de los componentes.ContainerStats/PodSandboxStats– Métricas de CPU, memoria, I/O.ListContainers/ListPodSandbox– Inventario de componentes activos.
Interacción directa con contenedores en ejecución:
ExecSync- Ejecutar comandos síncronos (kubectl exec)Attach- Conectarse a la salida estándar del contenedorPortForward- Redirección de puertos para acceso externo
containerd permite el uso de plugins para extender su funcionalidad. Existen varios tipos: snapshotter, almacenamiento o interfaces gRPC.
Para habilitar la comunicación entre kubelet y containerd, es necesario utilizar el plugin CRI.
La configuración de containerd en /etc/containerd/config.toml muestra cómo está habilitado el plugin CRI y configurado para usar runc como runtime por defecto:

Pause container
Un Pod puede contener uno o varios contenedores que comparten recursos, configuración y tienen la posibilidad de comunicarse entre sí.
Para poder lograrlo, es necesario que se ejecuten en el mismo namespace y control group. Para ello, introducimos el componente pause container.
pause container es un componente esencial en Kubernetes. Su función principal es mantener activo el namespace y el control group asociados a un Pod, incluso si los contenedores fallan o se reinician. De esta manera, varios contenedores comparten el mismo espacio de red y otros recursos.
Es extremadamente ligero (por ejemplo, la imagen mcr.microsoft.com/oss/kubernetes/pause:3.6 ocupa solo 484 kB). Ejecuta un bucle infinito escrito en C y gestiona señales como:
SIGINT/SIGTERM: señales que indican al proceso que debe finalizar de forma ordenada. El
pause containerlas gestiona para permitir una parada controlada del Pod.SIGCHLD: señal recibida cuando un proceso hijo termina. El
pause containerla maneja para limpiar correctamente los procesos hijos y evitar procesos zombis.
Estas señales permiten que el pause container actúe como un proceso init dentro del Pod, gestionando el ciclo de vida de los contenedores y asegurando la correcta recolección de procesos hijos.
En resumen, el pause container actúa como el proceso “padre” de todos los contenedores de un Pod, asegurando que los namespaces y cgroups permanezcan activos mientras el Pod exista. Si los procesos de los contenedores fallan o se reinician, el pause container mantiene el entorno aislado y listo para que los nuevos procesos se inicien en el mismo contexto.
Ejemplo práctico
En el siguiente ejemplo voy a mostrar cómo ver las diferentes jerarquías de procesos, cgroups y namespaces que se crean cuando ejecutamos un pod en un clúster de Kubernetes.
He desplegado un clúster de Kubernetes en Azure. En el siguiente enlace puedes ver cómo crear uno: https://learn.microsoft.com/en-us/azure/aks/learn/quick-kubernetes-deploy-portal.
Desplegamos el siguiente Pod en el clúster AKS:
kubectl create ns develop
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: web-with-logger
namespace: develop
spec:
containers:
- name: web-server
image: nginx:alpine
ports:
- containerPort: 80
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
volumeMounts:
- name: shared-logs
mountPath: /var/log/nginx
- name: log-reader
image: busybox
command: ["sh", "-c"]
args:
- |
while true; do
if [ -f /logs/access.log ]; then
tail -n 5 /logs/access.log
fi
sleep 10
done
volumeMounts:
- name: shared-logs
mountPath: /logs
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
volumes:
- name: shared-logs
emptyDir: {}
EOFPara poder acceder a la shell del nodo del clúster (sí, con los permisos correctos puedes acceder a la shell del nodo), utilizo el plugin kubectl node-shell.
El comando ps --forest -ef nos proporciona una vista completa del árbol de procesos, mostrando cómo todos los componentes se relacionan jerárquicamente desde systemd hasta nuestros contenedores de aplicación:

Podemos comprobar que el proceso padre de nuestro contenedor es el PID 14132 (este valor es del ejemplo y puede variar en cada entorno).
Ejecutando el comando pstree -pa se muestra la jerarquía de procesos:
systemd es el proceso raíz
containerd gestiona el runtime
containerd-shim-runc-v2 (un proceso por pod)
pause mantiene los namespaces del pod
web-server (nginx) / log-reader son los contenedores de aplicación
Ejecutando el comando pstree -pa -H 14132 -p 14132 --show-parents podemos ver claramente la jerarquía de procesos, donde systemd actúa como proceso raíz, containerd gestiona el runtime, y containerd-shim-runc-v2 maneja cada pod individual:

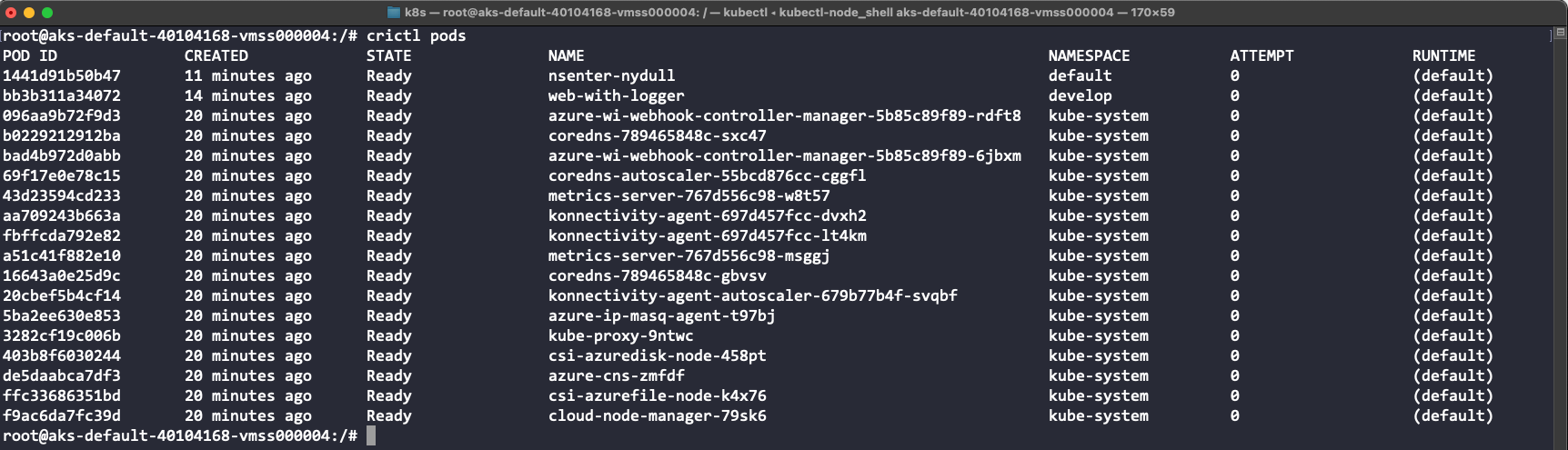
crictl es una aplicación de línea de comandos que permite interactuar con la interfaz CRI (Container Runtime Interface). Podemos utilizarla para inspeccionar los contenedores, consultar información o depurar un contenedor.
El comando crictl pods nos muestra todos los pods ejecutándose en el nodo, incluyendo tanto nuestro pod web-with-logger en el namespace develop como los pods del sistema:
El comando crictl ps --pod bb3b311a34072 podemos ver los contenedores nuestro Pod (no se muestra el pause container).

También nos permite obtener la configuración de todos los Pods que se están ejecutando en un namespace de Kubernetes: crictl inspectp --namespace develop.
El fichero contiene más de 800 líneas, puedes ver el archivo completo en el siguiente gist:
https://gist.github.com/fjvela/5374b33184c4ecbd39259e2d45dcf09d#file-crictl-inspectp-json
A continuación te muestro algunas de los datos más importantes que puedes encontrar en el fichero:
Configuración de Red:
IP del Pod:
10.244.0.153Gateway:
169.254.1.1DNS: Configurado para resolver servicios dentro del clúster
Namespace de red:
/var/run/netns/cni-d47bdb8a-6641-6cd2-d33e-55eb78bc2407
Jerarquía de Control Groups:
Ruta:
/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf07700a5_b996_4b1a_a3af_5f99ecb29549.sliceLímite de memoria: 268 MB (256 Mi total del Pod)
Límite de CPU: 100000/100000 (1 CPU core máximo)
Configuración de Seguridad:
Política Seccomp: Activa con 100+ syscalls permitidas
Capabilities: Conjunto restringido (CAP_CHOWN, CAP_SETUID, etc.)
Namespaces aislados: PID, IPC, UTS, Mount, Network
Otros datos importantes:
Logs:
/var/log/pods/develop_web-with-logger_f07700a5-b996-4b1a-a3af-5f99ecb29549Imagen pause:
mcr.microsoft.com/oss/kubernetes/pause:3.6
Entre los datos que nos muestra el comando, podemos observar la propiedad io.kubernetes.cri.sandbox-log-directory. El valor de la propiedad especifica dónde se almacenan los logs. Al explorar este directorio, encontramos los logs individuales de cada contenedor:

La carpeta /proc contiene el sistema de archivos virtual que almacena información de los procesos que se están ejecutando.
En esta carpeta se encuentra la información sobre los cgroups de nuestro proceso. El comando cat /proc/14132/cgroup muestra la ruta donde se almacena la configuración de cgroups:

Podemos observar que todos los procesos iniciados por containerd están dentro de la jerarquía de cgroups de containerd.
A continuación, comprobamos si los límites de memoria y CPU están configurados en los ficheros de configuración de cgroups. Al examinar los archivos de configuración, podemos verificar que los límites de memoria (134217728 bytes = 128Mi) y CPU (50000/100000 = 500m) están correctamente aplicados:

El comando systemd-cgls nos ayuda a visualizar la jerarquía de cgroups de forma gráfica y sencilla. Permite ver cómo están organizados los procesos y recursos dentro de los diferentes grupos de control, facilitando la identificación de los procesos hijos y su relación con los recursos asignados.

Por último, y no menos importante, comprobamos la configuración de los namespaces. Recordemos que su objetivo es aislar y compartir los recursos del sistema.
El siguiente script muestra los namespaces configurados para cada uno de los procesos que componen el Pod web-with-logger (pid 14132):
SHIM_PID=14132
for pid in $(ps --ppid $SHIM_PID --no-headers -o pid); do
echo "PID $pid namespaces:"
ls -la /proc/$pid/ns/ | grep -E "(net|pid|uts|ipc)" | awk '{print " " $9 ": " $11}'
echo ""
done
Podemos comprobar que los tres contenedores comparten los siguientes namespaces:
ipc: Permite que los contenedores compartan mecanismos de comunicación entre procesos (IPC), como semáforos y colas de mensajes.
net: Todos los contenedores del Pod comparten la misma pila de red, interfaces y dirección IP, lo que posibilita la comunicación interna mediante
localhost.uts: Compartir este namespace permite que todos los contenedores tengan el mismo hostname y nombre de dominio, facilitando la identificación dentro del Pod.
Gracias al uso de namespaces compartidos, los contenedores de un mismo Pod pueden comunicarse y compartir recursos de manera eficiente y segura.
Comprobamos la configuración de red de cada uno de los procesos:
SHIM_PID=14132
for pid in $(ps --ppid $SHIM_PID --no-headers -o pid); do
echo "Network interfaces from PID $pid:"
nsenter -t $pid -n ip addr show eth0 | grep inet
echo ""
done
Los tres contenedores utilizan la misma IP, lo que permite la comunicación entre ellos a través de localhost.
Comprobamos que los tres contenedores usan el mismo hostname:
SHIM_PID=14132
for pid in $(ps --ppid $SHIM_PID --no-headers -o pid); do
hostname=$(nsenter -t $pid -u hostname)
echo "PID $pid hostname: $hostname"
done
Conclusión
“Any sufficiently advanced technology is indistinguishable from magic” - Arthur C. Clarke
Parece trivial ejecutar un contenedor o un Pod en Kubernetes, pero la realidad es mucho más compleja.
El comando para ejecutar un contenedor lanza una coreografía perfecta de acciones en un ecosistema de herramientas y abstracciones que hemos explorado en detalle:
Primitivas del kernel: namespaces y cgroups
Runtimes de contenedores: runc y containerd
Interfaces estándar: CRI y OCI
Orquestación de contenedores: Kubernetes
Este sistema nos permite obtener portabilidad, escalabilidad y tolerancia a fallos, entre otras ventajas. Cada capa resuelve problemas reales y aporta valor a la solución final.
Sin embargo, cuando algo no funciona correctamente, esta misma complejidad puede convertir un problema simple en una pesadilla que requiere conocimiento profundo para poder resolverla.
Ahora sabes qué sucede realmente cuando Kubernetes hace su “magia”. Ese conocimiento es poder.
Referencias
https://github.com/containerd/containerd/blob/main/docs/cri/architecture.md
https://github.com/containerd/containerd/blob/main/docs/cri/config.md
https://github.com/kubernetes/cri-api/blob/master/pkg/apis/runtime/v1/api.proto
https://github.com/kubernetes/cri-api/blob/master/pkg/apis/services.go
https://github.com/kubernetes/kubernetes/blob/master/build/pause/linux/pause.c
https://kubernetes.io/blog/2024/05/01/cri-streaming-explained/
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
https://kubernetes.io/docs/tasks/debug/debug-cluster/crictl/